A knowledge graph is a structured model that connects entities, concepts, and relationships so information can be understood in context rather than as isolated records. In knowledge management, enterprise search, and AI systems, that context is what turns scattered data into usable knowledge. This is why knowledge graphs are becoming a core layer in modern information architecture.
Organizations across regions and industries face the same structural problem. Knowledge is spread across documents, wikis, CRM platforms, ticketing systems, internal portals, and employee expertise. Traditional systems can store that information, but they often fail to show how it connects. A knowledge graph solves that problem by mapping relationships between people, processes, documents, products, policies, and events. The result is better discovery, stronger search, and more reliable decision support.
What is a knowledge graph?
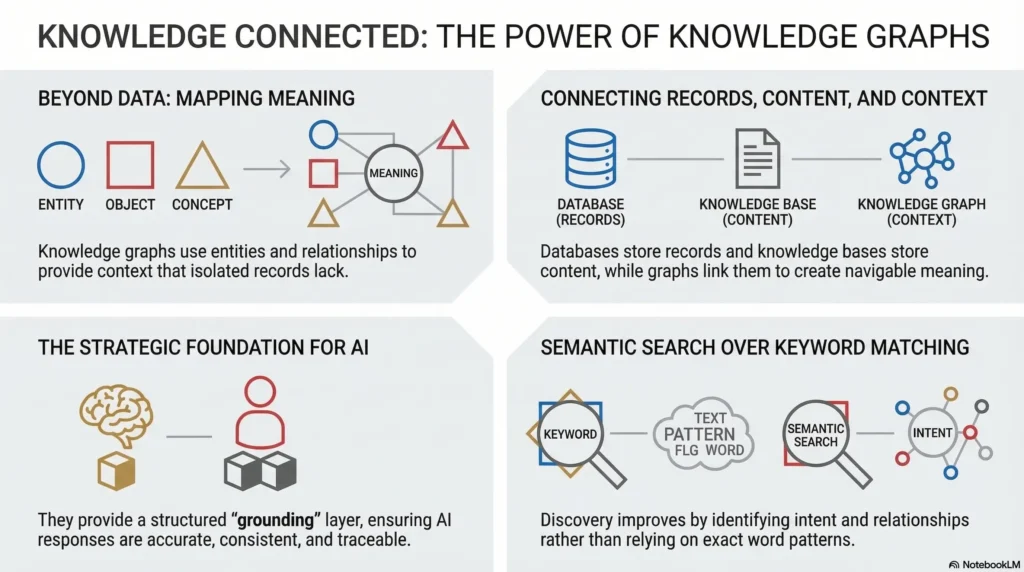
A knowledge graph is a semantic representation of information that connects entities and the relationships between them. The entities can be anything meaningful in a business or technical environment, such as employees, customers, products, departments, documents, topics, or systems. The relationships explain how those entities relate to one another.
For example, a knowledge graph can show that a policy applies to a region, a support article is related to a product version, an employee belongs to a team, or a customer account is connected to a service contract. That is the key difference between a knowledge graph and a simple database or document repository. A database stores data. A knowledge graph organizes meaning.
This makes knowledge graphs especially valuable for enterprises that need more than storage. They need context, consistency, and connection.
Why are knowledge graphs important in knowledge management?
Knowledge management is about capturing knowledge, organizing it, and making it available when people need it. Knowledge graphs strengthen every part of that process.
They improve discovery because content can be found through related entities, not only exact keywords. They improve reuse because employees can see what already exists before recreating it. They improve trust because the graph can show where information came from, who owns it, and how current it is. They improve decision-making because the system can reveal connected facts that are difficult to notice in isolated documents.
In large organizations, this is especially important. Information fragmentation creates delays, duplication, and inconsistency. A knowledge graph reduces those problems by linking internal knowledge assets into a navigable structure. In practical terms, this means a support agent can find the right answer faster, a new employee can discover the right policy more easily, and a manager can identify the right subject matter expert without depending on tribal knowledge.
For global enterprises, knowledge graphs are not a technical luxury. They are a knowledge infrastructure capability.
What are the core parts of a knowledge graph?
A knowledge graph usually contains five essential parts.
The first is the entity. An entity is any meaningful thing in the domain, such as a person, product, policy, document, or location.
The second is the relationship. Relationships explain how entities are connected. Examples include authored by, belongs to, reports to, applies to, depends on, or references.
The third is the schema or ontology. This defines the vocabulary and rules of the graph. It ensures that the graph has consistent meaning across the organization.
The fourth is metadata. Metadata adds useful context such as source, date, owner, version, confidence level, language, or region. This makes the graph more usable in real business conditions.
The fifth is governance. A knowledge graph only works when the data is curated, validated, and maintained over time. Without governance, the graph becomes noisy and loses trust.
These elements work together to create a semantic model that is both machine-readable and human-meaningful.
How is a knowledge graph different from a database or knowledge base?
This distinction matters because many teams confuse the three.
A database stores structured records. A knowledge base stores content, usually in the form of articles, procedures, and reference materials. A knowledge graph connects the knowledge across those systems and shows how the pieces relate.
A database can tell a team that a customer owns Product A. A knowledge graph can also show the support case history, contract details, account manager, renewal date, related issues, and relevant documentation. That connected view is much more useful for search, analytics, and AI.
A knowledge base may contain a troubleshooting article. A knowledge graph can connect that article to the relevant product, issue type, support workflow, and known exception. That turns a static article into a navigable knowledge asset.
The practical rule is simple. Use a database to store records, use a knowledge base to store content, and use a knowledge graph to connect meaning.
How do knowledge graphs improve search?
Search has changed. It is no longer only about exact keyword matching. Modern search systems try to understand meaning, intent, and context. Knowledge graphs make that possible.
When a user searches for something ambiguous, a knowledge graph helps the system interpret the query based on related entities and known relationships. When a user searches across a large enterprise knowledge base, the graph helps rank the most relevant answers, even if the words do not match exactly.
This is especially powerful in enterprise search. Employees do not want dozens of loosely related results. They want the right answer, the right document, or the right person as quickly as possible. Knowledge graphs make that possible by connecting search to semantics instead of relying only on text patterns.
That is one reason knowledge graphs are now central to semantic search and intelligent search experiences.
What is the role of knowledge graphs in AI?
Knowledge graphs are becoming more important as AI systems move into enterprise workflows. Large language models are strong at generating text, but they do not automatically understand an organization’s internal structure, terminology, or rules. They need grounding.
A knowledge graph provides that grounding. It gives AI systems structured context so they can retrieve relevant entities and relationships before generating a response. That improves relevance, consistency, and traceability.
This is especially valuable in enterprise AI, where accuracy matters. A model that answers from disconnected text alone may produce fluent but unreliable responses. A knowledge graph helps reduce that risk by tying responses to trusted internal knowledge. It can also support explainability, because the system can show how one piece of information connects to another.
For organizations building AI assistants, intelligent search, or retrieval-augmented workflows, knowledge graphs are becoming a foundational layer.
What are the main use cases for knowledge graphs?
Knowledge graphs have broad enterprise value because so many business problems depend on relationships.
In customer support, they connect products, known issues, tickets, troubleshooting steps, and support content. That improves case resolution and recommendations.
In sales and marketing, they connect accounts, contacts, buying groups, content, and campaign assets. That helps teams understand account context and deliver more relevant engagement.
In human resources, they connect employees, skills, roles, certifications, projects, and learning content. That supports expertise discovery and workforce planning.
In compliance and risk management, they connect policies, regulations, controls, exceptions, and evidence. That strengthens traceability and audit readiness.
In knowledge management, they connect documents, authors, topics, teams, decisions, and workflows. That helps organizations preserve and reuse institutional knowledge.
The strongest use cases are usually the ones where relationships matter more than isolated records.
How do organizations build a knowledge graph?
A successful knowledge graph project starts with a specific business problem. The objective should be clear from the beginning. For example, the goal may be to improve expert discovery, unify policy navigation, or connect support documentation.
Next, the organization defines the entities that matter to that use case. If the goal is expertise discovery, the graph may include people, skills, teams, projects, and evidence. If the goal is policy search, it may include documents, owners, regions, versions, and exceptions.
Then the relationships must be defined carefully. Good relationship design is what gives the graph its value. Relationships should reflect business meaning, not just technical structure.
After that, data is collected from relevant systems. These may include document repositories, intranet platforms, CRM systems, support tools, HR systems, and content management systems.
Finally, governance must be put in place. Ownership, validation, quality checks, update processes, and access controls all matter. A graph is only as good as the knowledge it contains and the discipline used to maintain it.
A knowledge graph should be treated as a living knowledge layer, not a one-time implementation.
What are the common mistakes companies make?
One common mistake is trying to model everything at once. That creates unnecessary complexity and slows adoption. It is better to start with one high-value use case and expand later.
Another mistake is using vague or inconsistent terminology. If one team uses customer and another uses client without a clear mapping, the graph becomes less reliable.
A third mistake is poor governance. If content is not curated and relationships are not validated, trust collapses quickly.
A fourth mistake is focusing only on the back end. If the graph does not improve search, discovery, or workflow for real users, adoption will remain low.
A fifth mistake is treating the graph as a one-time project rather than a continuously maintained knowledge system.
These mistakes are avoidable, but only if the graph is designed around actual business outcomes.
When should knowledge graphs be used, and when should they not?
Knowledge graphs are best used when relationships are central to the problem. That includes enterprise search, expert discovery, customer intelligence, recommendation systems, compliance mapping, and AI grounding.
They are less useful when the problem is simple and the data is flat. If a standard database can solve the problem cleanly and efficiently, a knowledge graph may be unnecessary. If the organization has too little data, too few relationships, or no clear retrieval challenge, the graph may not provide enough value.
The best rule is to use a knowledge graph when context creates value. If context does not matter, the graph may be more architecture than solution.
Why are knowledge graphs strategic for global enterprises?
Global enterprises deal with scale, complexity, and fragmentation. They operate across countries, business units, systems, and languages. That makes knowledge difficult to manage.
A knowledge graph gives the organization a shared semantic layer. It connects knowledge across silos and makes it easier to reuse across teams and regions. It also supports intelligent search and AI systems that need context to produce reliable results.
This is why knowledge graphs are increasingly important in modern enterprise architecture. They connect information, expertise, and process in a way that supports both human users and machine-driven systems.
For organizations that want to move from disconnected information to connected intelligence, knowledge graphs are a strategic advantage.
Final takeaway
Knowledge graphs are not just another data structure. They are a way of representing knowledge so that meaning, context, and relationships become visible. In knowledge management, that makes them powerful. In search, that makes them precise. In AI, that makes them trustworthy.
As enterprise systems continue to evolve, organizations that can connect knowledge across documents, people, processes, and systems will have a major advantage. Knowledge graphs are one of the most effective ways to build that advantage.
FAQs
What is a knowledge graph in simple terms?
A knowledge graph is a way of organizing information by connecting entities and their relationships so systems can understand context, not just isolated records.
How are knowledge graphs used in knowledge management?
Knowledge graphs connect content, people, and concepts, which makes knowledge easier to find, reuse, and understand across the organization.
What is the difference between a knowledge graph and a database?
A database stores records. A knowledge graph shows how those records relate to one another, which makes it more useful for context-heavy problems.
Why are knowledge graphs important for AI?
They provide structured context that helps AI systems retrieve better information, reduce ambiguity, and generate more accurate responses.
What are common enterprise use cases for knowledge graphs?
Common use cases include enterprise search, customer support, expertise discovery, recommendation systems, compliance mapping, and knowledge management.
What tools are used to build knowledge graphs?
Organizations often use graph databases and semantic technologies such as Neo4j, Amazon Neptune, RDF, and OWL-based systems.